FLOPPAR
Den aktuella versionen av sidan har ännu inte granskats av erfarna bidragsgivare och kan skilja sig väsentligt från
versionen som granskades den 30 december 2021; kontroller kräver
18 redigeringar .
FLOPS (även floppar , flopp/s , floppar eller flopp/s ; en akronym från engelska FL oating-point OP erations per Second , uttalas som floppar ) är en icke-systemenhet som används för att mäta datorprestanda , som visar hur många flyttal operationer per sekund utförs av detta datorsystem. Eftersom moderna datorer har en hög prestandanivå är de härledda kvantiteterna från floppar, som bildas genom att använda SI-prefix , vanligare .
FLOP eller FLOPS
Det råder oenighet om huruvida det är tillåtet att använda ordet FLOP från engelskan. FL oating point OP eration i singular (och varianter som flopp eller flopp ). Vissa människor tror att FLOP (flop) och FLOPS (flops eller flopp/s) är synonymer, andra tror att FLOP bara är antalet flyttalsoperationer (till exempel krävs för att köra ett givet program), och FLOPS är ett mått på prestanda, förmågan att utföra ett visst antal flyttalsoperationer per sekund.
Flops som ett mått på prestanda
Liksom de flesta andra prestandaindikatorer bestäms detta värde genom att köra ett testprogram på testdatorn som löser ett problem med ett känt antal operationer och beräknar tiden då det löstes. Det mest populära riktmärket idag är LINPACK-riktmärkena , närmare bestämt HPL som används i TOP500 superdatorrankingen .
En av de viktigaste fördelarna med att mäta prestanda i floppar är att denna enhet, till vissa gränser, kan tolkas som ett absolut värde och beräknas teoretiskt, medan de flesta andra populära mått är relativa och låter dig utvärdera systemet som testas endast i jämförelse. med ett antal andra. Denna funktion gör det möjligt att använda olika algoritmer för att utvärdera resultatet av arbetet , samt för att utvärdera prestandan hos datorsystem som ännu inte finns eller är under utveckling.
Tillämpningsgränser
Trots den uppenbara otvetydigheten är floppar i verkligheten ett ganska dåligt mått på prestanda, eftersom själva definitionen redan är tvetydig. Under "flyttalsoperationen" kan en hel del olika begrepp döljas, för att inte tala om att ordlängden på operanderna spelar en betydande roll i dessa beräkningar , vilket inte heller anges någonstans. Dessutom påverkas floppar av många faktorer som inte är direkt relaterade till prestandan hos beräkningsmodulen, såsom bandbredden för kommunikationskanaler med processormiljön , prestanda för huvudminnet och synkroniseringen av cacheminnet hos olika nivåer.
Allt detta leder i slutändan till det faktum att resultaten som erhålls på samma dator med olika program kan skilja sig betydligt; Dessutom, med varje ny försök, kan olika resultat erhållas med samma algoritm. Delvis löses detta problem genom en överenskommelse om användning av enhetliga testprogram (samma LINPACK) med ett genomsnitt av resultaten, men med tiden "växer" datorernas kapacitet ur ramverket för det accepterade testet och det börjar ge artificiellt låga resultat, eftersom den inte använder de senaste funktionerna hos datorenheter. Och för vissa system kan allmänt accepterade tester inte tillämpas alls, vilket gör att frågan om deras prestanda förblir öppen.
Så den 24 juni 2006 presenterades superdatorn MDGrape-3 , utvecklad vid det japanska forskningsinstitutet RIKEN ( Yokohama ), med en rekord teoretisk prestanda på 1 petaflops , för allmänheten . Den här datorn är dock inte en dator för allmänt bruk och är anpassad för att lösa ett snävt antal specifika uppgifter, medan standard LINPACK-testet inte kan utföras på den på grund av dess arkitekturs egenheter.
Hög prestanda för specifika uppgifter visas också av grafikprocessorerna på moderna grafikkort och spelkonsoler . Till exempel är den deklarerade prestandan för videoprocessorn på PlayStation 3 -spelkonsolen 192 gigaflops [3] , och videoacceleratorn på Xbox 360 är 240 gigaflops [3] , vilket är jämförbart med tjugo år gamla superdatorer. Så höga siffror förklaras av att prestanda anges på 32-bitars nummer [4] [5] , medan för superdatorer brukar prestanda på 64-bitars data anges [6] [7] . Dessutom är dessa set-top-boxar och videoprocessorer designade för operationer med tredimensionell grafik som lämpar sig väl för parallellisering, men dessa processorer kan inte utföra många allmänna uppgifter och deras prestanda är svår att bedöma med det klassiska LINPACK-testet [8] och svårt att jämföra med andra system.
Toppprestanda
För att beräkna det maximala antalet floppar för en processor måste man ta hänsyn till att moderna processorer i var och en av sina kärnor innehåller flera exekveringsenheter av varje typ (inklusive de för flyttalsoperationer) som arbetar parallellt och kan exekvera mer än en instruktion per klocka. Denna arkitektoniska funktion kallas superskalär och dök upp första gången i CDC 6600 -datorn 1964. Massproduktion av datorer med superskalär arkitektur började med lanseringen av Pentium-processorn 1993. Processorn från det sena 2000-talet, Intel Core 2 , är också superskalär och innehåller 2 64-bitars flyttalsenheter som kan utföra 2 relaterade operationer (multiplikation och efterföljande addition, MAC ) i varje cykel, vilket teoretiskt tillåter toppprestanda upp till 4 operationer per 1 cykel i varje kärna [9] [10] [11] . För en processor med 4 kärnor (Core 2 Quad) och som arbetar med en frekvens på 3,5 GHz är den teoretiska prestandagränsen 4x4x3,5 = 56 gigaflops, och för en processor med 2 kärnor (Core 2 Duo) och som arbetar med en frekvens på 3 GHz - 2x4x3 = 24 gigaflops, vilket stämmer väl överens med de praktiska resultaten som erhållits i LINPACK-testet.
AMD Phenom 9500 sAM2+ 2,2 GHz: 2200 MHz × 4 kärnor × 4⋅10 −3 = 35,2 GFlops
För Core 2 Quad Q6600: 2400 MHz × 4 kärnor × 4⋅10 −3 = 38, 4 gigaflops.
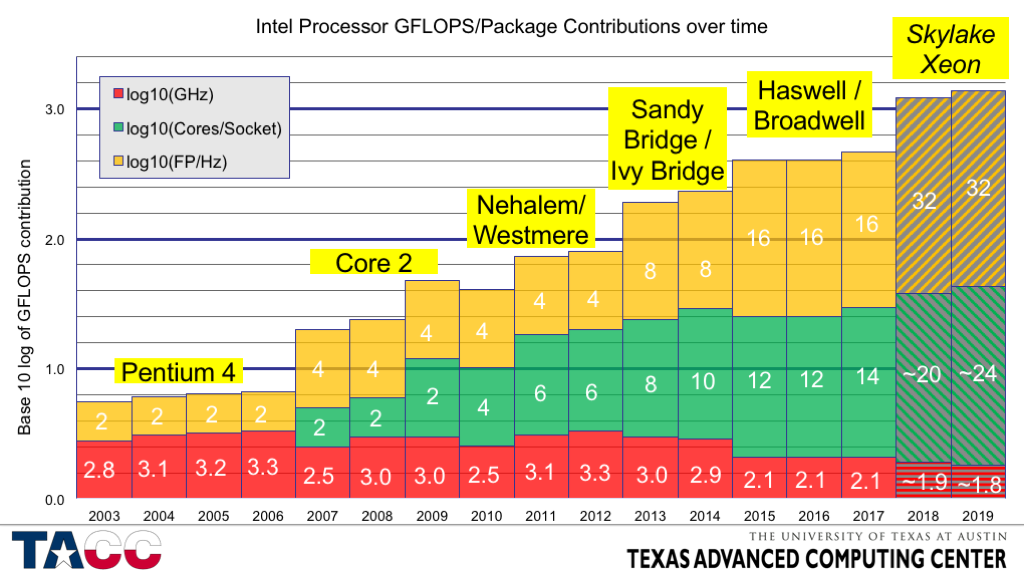
Nyare processorer kan utföra upp till 8 (t.ex. Sandy and Ivy Bridge , 2011-2012, AVX) eller upp till 16 ( Haswell och Broadwell, 2013-2014, AVX2 och FMA3) 64-bitars flyttalsoperationer per klocka (på varje kärna) [11] . Framtida processorer förväntas utföra 32 operationer per klocka (Intel Xeon Skylake, Xeon *v5, 2015, AVX512) [12]
Sandy and Ivy Bridge med AVX: 8 Flops/klocka dubbel precision [13] , 16 Flops/klocka enkel precision
Intel Core i7 2700: / Intel Core i7 3770: 8*4*3900 MHz = 124,8 Gflops topp dubbel precision, 16 *4 *3900 = 249,6 Gflops enkel precisionstopp.
Intel Haswell / Broadwell med AVX2 och FMA3: 16 floppar/klocka dubbel precision [13] ; 32 enkelprecisionsflopar/klocka
Intel Core i7 4770: 16*4*3900 MHz = 249,6 Gflops topp dubbel precision, 32*4*3900 = 499,2 Gflops topp enkelprecision.
Skäl till utbredd användning
Trots ett stort antal betydande brister, fortsätter floppar att användas framgångsrikt för att utvärdera prestanda baserat på resultaten av LINPACK-testet. Skälen till sådan popularitet beror för det första på det faktum att floppen, som nämnts ovan, är ett absolut värde. Och för det andra kommer många uppgifter inom ingenjörsvetenskap och vetenskaplig praktik i slutändan ner på att lösa system med linjära algebraiska ekvationer , och LINPACK-testet är baserat på att mäta hastigheten för att lösa sådana system. Dessutom är de allra flesta datorer (inklusive superdatorer) byggda enligt den klassiska arkitekturen med hjälp av standardprocessorer, vilket möjliggör användning av allmänt accepterade tester med stor tillförlitlighet.
I olika algoritmer kan det, förutom möjligheten att utföra ett stort antal matematiska operationer i processorkärnan, vara nödvändigt att överföra stora mängder data genom minnesundersystemet, och deras prestanda kommer att vara kraftigt begränsad på grund av detta, t.ex. , som i nivåerna 1 och 2 i BLAS-biblioteken [11] . Algoritmerna som används i tester som LINPACK (BLAS nivå 3) har dock ett högt dataåteranvändningsförhållande, de tar mindre än 1/10 av den totala tiden att överföra data mellan processorn och minnet, och de uppnår vanligtvis typiska prestanda upp till 80 -95% av teoretiskt maximum.
Prestandaöversikt över verkliga system
På grund av den stora spridningen av LINPACK-testresultat ges ungefärliga värden genom medelvärdesindikatorer baserade på information från olika källor. Prestanda för spelkonsoler och distribuerade system (som har en snäv specialisering och som inte stöder LINPACK-testet) ges för referensändamål i enlighet med siffrorna som deklarerats av deras utvecklare. Mer exakta resultat med specifika systemparametrar kan erhållas till exempel på The Performance Database Server .
Superdatorer
Uno
Kilo
Mega
Giga
Tera
Peta
- Cray Jaguar ( 2008 ) - 1 059 petaflops
- IBM Roadrunner ( 2008 ) - 1.042 petaflops [16]
- Lomonosov ( 2011 , NIVC MSU) - 1,3 petaflops
- Jaguar Cray XT5-HE ( 2009 ) - 1 759 petaflops
- T-Platform A-Class Cluster (Lomonosov-2, november 2014, forsknings- och utvecklingscentrum vid Moscow State University) - 1,85 petaflops (i 5 ställ) [17] [18] [19] .
- Tianhe-1A ( 2010 ) - 2,57 petaflops
- Christofari (2019) - 6,7 petaflops ( 75 -nod NVIDIA DGX-2 kluster ) [20] [21] [22]
- Fujitsu K dator ( 2011 ) - 8.16-10.51 petaflops [23]
- IBM Sequoia ( 2012 ) - 16.32 petaflops [24]
- Cray Titan (ex. Cray Jaguar ; 2012 ) - >17.59 petaflops [25]
- Chervonenkis (2021) - 21 530 petaflops
- Tianhe-2 ( 2013 ) - 33,86 petaflops [26]
- Sunway TaihuLight (2016) - 93 petaflops
- Summit (2018) - 122,3 petaflops
- Fugaku (2020) - 442,01 petaflops
Exa
Persondatorprocessorer
Dubbel precision toppprestanda [27]
- Zilog Z80 + AMD Am9512 matematisk coprocessor , 3 MHz (1977-1980) ~ 1-2 kflops [28]
- Intel 80486DX/DX2 (1990-1992) - upp till 30-50 Mflop/s [29]
- Intel Pentium 75-200 MHz (1996) - upp till 75-200 Mflop/s [29] [30]
- Intel Pentium III 450-1133 MHz (1999-2000) - upp till 450-1113 Mflop/s [29] [30]
- Intel Pentium III-S (2001) 1 - 1,4 GHz - upp till 1 - 1,4 Gflop/s [30]
- MCST Elbrus 2000 300 MHz (2008) - 2,4 Gflop/s
- Intel Atom N270, D150 1,6 GHz (2008-2009) - upp till 3,2 Gflop/s [29]
- Intel Pentium 4 2,5-2,8 GHz (2004) - upp till 5 - 5,6 Gflop/s [29]
- MCST Elbrus-2C+ 500 MHz, 2 kärnor (2011) - 8 Gflop/s
- AMD Athlon 64 X2 4200+ 2,2 GHz, 2 kärnor ( 2006 ) - 8,8 Gflops/s
- Intel Core 2 Duo E6600 2,4 GHz 2 kärna (2006) - 19,2 Gflop/s
- MCST Elbrus-4S (1891VM8Ya, Elbrus v.3) 800 MHz, 4 kärnor (2014) — 25 Gflop/s [31]
- Intel Core i3 -2350M 2,3 GHz 2 kärna (2011) - 36,8 Gflop/s
- Intel Core 2 Quad Q8300 2,5 GHz 4 kärnor (2008) - 40 Gflop/s
- AMD Athlon II X4 640 3,0 GHz 4 Core ( 2010 ) - 48 Gflop/s
- Intel Core i7-975 XE ( Nehalem ) 3,33 GHz 4 kärnor (2009) - 53,3 Gflop/s
- AMD Phenom II X4 965 BE 3,4 GHz 4 kärnor ( 2009 ) - 54,4 Gflop/s
- AMD Phenom II X6 1100T 3,3 GHz 6 kärnor (2010) - 79,2 Gflop/s
- Intel Core i5 -2500K ( Sandy Bridge ), 3,3 GHz, 4 kärnor (2011) - 105,6 Gflop/s
- MCST Elbrus-8S (Elbrus v.4) 1,3 GHz, 8 kärnor (2016) — 125 Gflop/s [32] [33]
- AMD FX-8350 4 GHz 8 kärnor (2012) - 128 Gflop/s [34]
- Intel Core i7 -4930K ( Ivy Bridge ) 3,4 GHz 6 kärnor (2013) - 163 GFlops/s
- Loongson-3B1500 ( MIPS64 ), 1,5 GHz, 8 kärnor (2016) - upp till 192 GFlop/s [35]
- AMD Ryzen 7 1700X ( Zen ) 3,4 GHz 8-Core (2017) [36] - 217 GFlops [37]
- MCST Elbrus-8SV (Elbrus v.5) 1,5 GHz, 8 kärnor (2020 - plan) [38] - 288 Gflop/s [39] [40]
- IBM Power8 4,4 GHz, 12 kärnor (2013), 290 Gflop/s
- Intel Core i7-5960X (Extreme Edition Haswell -E), 3,0 GHz, 8 kärnor (2014) - 384 Gflop/s (upp till 350 Gflop/s kan uppnås i praktiken [41] )
- Intel Core i9-9900k ( Coffee Lake ), 3,6 GHz, 8 kärnor (2018) [42] - 460 Gflops [43]
- AMD Ryzen 7 3700X ( Zen 2 ), 3,6 GHz, 8 kärnor (2019) [44] - 460 GFlops [43]
- MCST Elbrus-12S 2 GHz, 12 kärnor (2020 - plan) - 576 Gflop/s
- MCST Elbrus-16S 2 GHz, 16 kärnor (2021 - plan) - 768 Gflop/s [45] .
- AMD Ryzen 9 3950X ( Zen 2 ) 3,5 GHz 16 kärnor (2019) [46] - 896 GFlops/s [47]
- AMD EPYC 7H12 ( Zen 2 ), 3,3 GHz, 64 kärnor (2019) [48] - 4,2 teraflops [49]
Antal FLOP per klocka för olika arkitekturer
För ett antal processormikroarkitekturer är det maximala antalet flytande operationer som exekveras per klocka på en kärna känt. Listan nedan listar mikroarkitekturnamn, inte processorfamiljer.
(enkel) - enkel precision; (dubbel) - dubbel precision [50]
- Intel P5 & P6 (inga ISE) + Pentium Pro & Pentium II = 1 (enkel); 1 (dubbel)
- P6 (endast Pentium III) = 4 (enkel); 1 (dubbel)
- Bonnell ( Atom ) = 4( Singel ); 1 ( dubbel )
- NetBurst = 4 (enkel); 2 (dubbel)
- Pentium M & Enhanced Pentium M = 4 (enkel); 2 (dubbel)
- Core, Penryn, Nehalem & Westmere = 8 (singel); 4 (dubbel)
- Sandy Bridge & Ivy Bridge = 16 (singel); 8 (dubbel)
- Haswell, Broadwell, Skylake, Kaby Lake & Coffee Lake = 32 (singel); 16 (dubbel)
- Skylake-X, Skylake-SP, Cascade Lake-X (Xeon Gold & Platinum) = 64 (singel); 32 (dubbel) [51] [52]
- Bonnell, Saltwell, Silvermont & Airmont = 6 (singel); 1,5 (dubbel)
- MIC ("Knights Corner" Xeon Phi) = 32 (singel); 16 (dubbel)
- MIC ("Knights Landing" Xeon Phi) = 64 (singel); 32 (dubbel) [51]
- AMD K5 & K6 = 0,5 (enkel); 0,5 (dubbel)
- K6-2 & K6-III = 4 (enkel); 0,5 (dubbel)
- K7 = 4 (enkel); ? (dubbel)
- K8 = 4 (enkel); 2 (dubbel)
- K10/Stjärnor = 8 (singel); 4 (dubbel)
- Husky = 8 (singel); 4 (dubbel)
- Bulldozer, Piledriver, Steamroller & Grävmaskin (Totalt per par kärnor - modul [53] ) = 16 (enkel); 8 (dubbel)
- Bobcat = 4 (singel); 1,5 (dubbel)
- Jaguar, Puma och Puma+ = 8 (singel); 3 (dubbel)
- Zen, Zen+ = 16 (singel); 8 (dubbel)
- Zen 2 = 32 (singel); 16 (dubbel)
- MCST Elbrus 2000 (E2K) = 16 (enkel); 8 (dubbel) [54] [55]
- Elbrus version 3 = 16 (enkel); 8 (dubbel)
- Elbrus version 4 = 24 (enkel); 12 (dubbel) [56] [57]
- Elbrus version 5 = 48 (enkel); 24 (dubbel) [58] [59]
Fickdatorprocessorer
- PDA baserad på Samsung S3C2440 400 MHz-processor ( ARM9- arkitektur ) - 1,3 megaflops
- Intel XScale PXA270 520 MHz - 1,6 megaflops
- Intel XScale PXA270 624 MHz - 2 megaflops
- Samsung Exynos 4210 2x1600 MHz - 84 megaflops
- Apple A6 - 645 megaflops (LINPACK uppskattning)
- Apple A7 - 833 megaflops (LINPACK uppskattning) [60]
- Apple A8 - 1,4 gigaflops [61]
- Apple A10 - 365 gigaflops (fp32), 91 gigaflops (fp64) [62]
- Apple A14 - 824 gigaflops (fp32), 206 gigaflops (fp64) [62]
Distribuerade system
- Bitcoin - har en betydande mängd specialiserade datorresurser, men löser bara heltalsproblem (beräknar SHA256-hashsumman ) . Nästan alla miniräknare är implementerade i form av speciella anpassade mikrokretsar (ASIC), som inte är tekniskt kapabla att utföra beräkningar på flyttal. Därför är det för närvarande felaktigt att utvärdera Bitcoin-nätverket med hjälp av floppar. [63] [64] [65] Tidigare, fram till 2011, användes endast CPU :er och GPU :er i nätverket , som kan hantera både heltalsdata och flytande data, och floppuppskattningen erhölls från hash/s-måttet med hjälp av en empirisk faktor på 12, 7 tusen. [66] [67] Till exempel, från och med april 2011, uppskattades kraften i nätverket med denna metod till cirka 8 petaflops. [68]
- Folding@home är över 2,6 exaflops den 23 april 2020, vilket gör det till det kraftfullaste och största distribuerade datorprojektet i världen.
- BOINC - över 41,5 petaflops i mars 2020 [69]
- SETI@home - 0,66 petaflops (för 2013) [70]
- Einstein@Home — mer än 5,2 petaflops i mars 2020 [71]
- Rosetta@home - mer än 1,4 petaflops i mars 2020.
Spelkonsoler
Flyttalsoperationer på 32-bitars data specificerad
- Sega Dreamcast - 1,4 gigaflops
- Nintendo GameCube - 1,9 gigaflops ( CPU ), 8,6 gigaflops ( ATI-AMD "Flipper" GPU ) [72]
- Sony PlayStation Portable - 2,6 gigaflops [73]
- Nintendo Wii - 2,9 gigaflops (CPU) [74]
- Microsoft Xbox - 2.9 gigaflops (Intel Pentium III 733 Mhz CPU), 80.0 gigaflops (Nvidia XGPU 233 Mhz GPU) [72]
- Sony PlayStation 2 - 6,2 gigaflops
- Microsoft Xbox 360 - 115.2 gigaflops (IBM Xenon CPU ), 240 gigaflops (ATI-AMD Xenos GPU )
- Sony PlayStation 3 - 230,4 gigaflops enkel precision och upp till +15 gigaflops dubbel precision (CPU Cell BE ) [75] [76]
- Nintendo Wii U - 352 gigaflops (GPU, förmodligen) [77]
- Sony PlayStation 3 - 400,4 gigaflops (GFlops) RSX Nvidia G70 550 MHz [3]
- Microsoft Xbox One - 1.23 teraflops (GPU) [78]
- Sony PlayStation 4 (AMD Radeon GPU) - 1,84 teraflops [79]
- Sony PlayStation® 4 Pro - 4.20 TFLOPS (AMD Radeon GPU) [80]
- Microsoft Xbox One X - 6 teraflops (GPU)
- Sony PlayStation 5 ( Radeon Navi GPU , med RDNA2- arkitektur) - 10,3 teraflops [81]
- Microsoft Xbox Series X - 12 teraflops (GPU) [82]
GPU:er
Teoretisk prestanda (FMA; gigaflops):
Man och kalkylator
Det är ingen slump att en miniräknare faller i samma kategori som en person, för även om det är en elektronisk enhet som innehåller en processor, ett minne och in- och utmatningsenheter är dess funktionssätt fundamentalt annorlunda än en dators. Kalkylatorn utför den ena operationen efter den andra med den hastighet med vilken de efterfrågas av den mänskliga operatören. Tiden som går mellan operationerna bestäms av mänskliga förmågor och överstiger avsevärt tiden som går åt direkt på beräkningar. Vi kan säga att den genomsnittliga prestandan för de enklaste konventionella fickkalkylatorerna är cirka 10 floppar eller mer.
Om du inte tar undantagsfall (se fenomenal räknare ), så utför en vanlig person, som bara använder en penna och papper, flyttalsoperationer mycket långsamt och ofta med ett stort fel, och talar alltså om en persons prestanda som en datorenhet , måste man använda sådana enheter, som milliflops och till och med mikroflops.
Se även
Anteckningar
- ↑ Ny twist Arkiverad 11 september 2013 på Wayback Machine Byrd Kiwi , PC World, nr 07, 2012: "Om den nuvarande utvecklingstakten för superdatorer fortsätter, kommer nästa prestandamilstolpe att vara 1 exaflops, eller en kvintiljon (10) ^18) operationer per sekund, som förväntas uppnås 2019 ... man tror att en dator med en prestanda på en zettaflops (10^21, eller sextillion operationer) kan byggas runt 2030. Dessutom finns villkor redan i lager för nästa datorgräns - yottaflops (10^ 24) och xeraflops (10^27)."
- ↑ Peta, exa, zetta, yotta... Arkiverad 3 december 2013 på Wayback Machine Byrd Kiwi , Computerra, Datum: 16 juli 2008: "Denna gräns bör följas av zettaflops (10^21), yottaflops (10^ 24 ) och xeraflops (10^27)."
- ↑ 1 2 3 PLAYSTATION 3のグラフィックスエンジン RSX . Datum för åtkomst: 30 december 2016. Arkiverad från originalet den 17 september 2016. (obestämd)
- ↑ http://ixbtlabs.com/articles3/video/rv670-part1-page1.html Arkiverad 13 januari 2010 på Wayback Machine flyttals-ALUer .. stöd för FP32-precision
- ↑ Arkiverad kopia (länk ej tillgänglig) . Hämtad 17 augusti 2009. Arkiverad från originalet 5 juli 2009. (obestämd) dessa är enkla precisions GPU-toppnummer
- ↑ Arkiverad kopia (länk ej tillgänglig) . Hämtad 17 augusti 2009. Arkiverad från originalet 15 oktober 2009. (obestämd) HPL är ett mjukvarupaket som löser ett tätt linjärt system i dubbel precision (64 bitar)
- ↑ [1] Arkiverad 1 september 2009 på Wayback Machine [2] Arkiverad 1 september 2009 på Wayback Machine HPL FAQ-poster för precision
- ↑ Utnyttja prestanda hos 32-bitars FP Arithmetic för att erhålla 64-bitars noggrannhet (återvända iterativa förfining för linjära system) Arkiverad 4 december 2008 på Wayback Machine
- ↑ SSE, SSE2 & SSE3 max genomströmning: 4 flopp/cykel . Hämtad 28 september 2017. Arkiverad från originalet 16 mars 2012. (obestämd)
- ↑ Nettoresultatet är att du nu kan bearbeta 2 DP-adderingar och 2 DP-multiplikationer per klocka, eller 4 FLOPS per cykel. (DP) . Tillträdesdatum: 20 juli 2010. Arkiverad från originalet den 24 maj 2010. (obestämd)
- ↑ 1 2 3 Jack Dongarra. Adaptiva linjära lösare och egenlösare (engelska) (inte tillgänglig länk) . Argonne Training Program on Extreme-scale Computing . Argonne National Laboratory (13 augusti 2014). Hämtad 13 april 2015. Arkiverad från originalet 24 april 2016.
- ↑ Jack Dongarra, Peak Performance - Per Core Arkiverad 22 december 2015 på Wayback Machine / A Look at High Performance Computing, 2015-10-15
- ↑ 1 2 http://sites.utexas.edu/jdm4372/2016/11/22/sc16-invited-talk-memory-bandwidth-and-system-balance-in-hpc-systems/ Arkiverad 2 februari 2017 på Wayback Maskin http://sites.utexas.edu/jdm4372/files/2016/11/Slide20.png Arkiverad 2 februari 2017 på Wayback Machine
- ↑ Datorkraft: från den första datorn till den moderna superdatorn . Hämtad 19 mars 2020. Arkiverad från originalet 19 mars 2020. (obestämd)
- ↑ The Emergence of Numerical Weather Prediction: från Richardson till ENIAC Arkiverad 2 december 2013 på Wayback Machine , 2011
- ↑ IBM har skapat den mest kraftfulla superdatorn i världen _ _
- ↑ T-PLATTFORM A-KLASS CLUSTER, XEON E5-2697V3 14C 2,6GHZ, INFINIBAND FDR, NVIDIA K40M Arkiverad 29 november 2014 på Wayback Machine // Top 500, november 2014
- ↑ Nytt betyg av TOP500 superdatorer Arkivexemplar av 21 november 2014 på Wayback Machine // Computerra, 18 november 2014: "... ett kluster av A-klass skapat av T-Platforms för Research Computing Center vid Moscow State University. "
- ↑ Den nya superdatorn på MSU gick in i Top500 Archival kopia daterad 17 november 2016 på Wayback Machine // Data Center World, Open Systems, 11/19/2014: "Den nya MSU superdatorn har bara fem datorställ med 1280 noder baserat på 14-kärniga Intel Xeon E5-processorer -2697 v3 och NVIDIA Tesla K40 acceleratorer med en total RAM-kapacitet på mer än 80TB. … Varje rack i en superdator förbrukar cirka 130 kW.”
- ↑ Christofari - NVIDIA DGX-2, Xeon Platinum 8168 24C 2.7GHz, Mellanox InfiniBand EDR, NVIDIA Tesla V100 Arkiverad 3 januari 2020 på Wayback Machine - top500, 2019-11
- ↑ Videopresentation av Christofaris superdator . Sbermoln. Hämtad 27 december 2019. Arkiverad från originalet 17 december 2019. (ryska)
- ↑ Sberbank skapade den mest kraftfulla superdatorn i Ryssland . RIA Novosti (20191108T1123+0300Z). Datum för åtkomst: 8 november 2019. Arkiverad från originalet den 8 november 2019. (ryska)
- ↑ Japansk superdator överträffar kinesisk arkivkopia daterad 5 november 2011 på Wayback Machine (ryska)
- ↑ Lawrence Livermores Sequoia Supercomputer Towers ovanför resten i senaste TOP500-listan Arkiverad 11 september 2017 på Wayback Machine , TOP500 News Team | 16 juli 2012
- ↑ Agam Shah (IDG News), Titan superdator når 20 petaflops processorkraft Arkiverad 3 juli 2017 på Wayback Machine // PCWorld, Computers, 29 oktober 2012
- ↑ Lovande funktioner i Tianhe-2 Arkiverad 28 november 2014 på Wayback Machine // Open Systems, nr 08, 2013
- ↑ Enkelprecisionsprestandan för de flesta processorer är exakt 2 gånger högre än de angivna värdena.
- ↑ Från 1200 till 4900 processorcykler för att exekvera en dubbel precisionsinstruktion beroende på deras typ, enkla precisionsoperationer utfördes ungefär 10 gånger snabbare: https://datasheetspdf.com/pdf/1344616/AMD/Am9512/1 Arkiverad kopia från 26 december , 2019 på Wayback Machine (sida 4)
- ↑ 1 2 3 4 5 Ryan Crierie. http://www.alternatewars.com/BBOW/Computing/Computing_Power.htm (engelska) . Alternativa krig (13 mars 2014). Tillträdesdatum: 23 januari 2015. Arkiverad från originalet 23 januari 2015.
- ↑ 1 2 3 Jack J. Dongarra. Prestanda för olika datorer som använder standardprogramvaran för linjära ekvationer ( 15 juni 2014). Hämtad 23 januari 2015. Arkiverad från originalet 17 april 2015.
- ↑ Elbrus-4C mikroprocessor (otillgänglig länk) . MCST. Hämtad 28 juni 2015. Arkiverad från originalet 4 juni 2014. (obestämd)
- ↑ Centralprocessor "Elbrus-8S" (TVGI.431281.016) . JSC "MCST" . Hämtad 16 december 2017. Arkiverad från originalet 30 mars 2018. (obestämd)
- ↑ Sex 64-bitars FMAC - block per kärna: 8 x 1,3 x 6 x 2 = 124,8 GFlops/s dubbel precision toppprestanda
- ↑ Två 128-bitars FMAC - block i varje modul som kombinerar ett par kärnor som arbetar med en frekvens på 4 GHz: 4x4x2x2x128/64 = 128 GFlops/s toppprestanda i dubbelprecisionsberäkningar
- ↑ Alex Voica. Nya MIPS64-baserade Loongson-processorer bryter prestandabarriären (engelska) (nedlänk) (3 september 2015). Hämtad 4 februari 2017. Arkiverad från originalet 5 februari 2017.
- ↑ Arkiverad kopia . Hämtad 26 december 2019. Arkiverad från originalet 27 juni 2019. (obestämd)
- ↑ Två 128-bitars FMAC - block per kärna: 8 x 3,4 x 2 x 2 x 128/64 = 217,6 Gflops/s dubbel precision toppprestanda
- ↑ Mikroprocessor "Elbrus-8SV" (TVGI.431281.023) . JSC "MCST" . Datum för åtkomst: 16 december 2017. Arkiverad från originalet 27 december 2019. (obestämd)
- ↑ Första Elbrus-8SV . Hämtad 23 september 2017. Arkiverad från originalet 23 september 2017. (obestämd)
- ↑ Sex 128-bitars FMAC - block per kärna: 8 x 1,5 x 6 x 2 x 128/64 = 288 Gflops med dubbel precision med toppprestanda
- ↑ Linpack prestanda Haswell E (Core i7 5960X och 5930K) - Puget Custom Computers . Tillträdesdatum: 15 januari 2015. Arkiverad från originalet den 27 mars 2015. (obestämd)
- ↑ Intel® Core™ i9-9900K-processor (16 MB cache, upp till 5,00 GHz) Produktspecifikationer . Hämtad 26 december 2019. Arkiverad från originalet 5 mars 2021. (obestämd)
- ↑ 1 2 Två 256-bitars FMAC - block per kärna: 8 x 3,6 x 2 x 2 x 256/64 = 460 GFlop/s
- ↑ Arkiverad kopia . Hämtad 26 december 2019. Arkiverad från originalet 27 juni 2019. (obestämd)
- ↑ Elbrus 16C mikroprocessor (första tekniska prov mottagna) . Hämtad 30 januari 2020. Arkiverad från originalet 4 januari 2020. (obestämd)
- ↑ Arkiverad kopia . Hämtad 26 december 2019. Arkiverad från originalet 24 juli 2019. (obestämd)
- ↑ Två 256-bitars FMAC - block per kärna: 16 x 3,5 x 2 x 2 x 256/64 = 896 GFlops/s
- ↑ Specifikationer för AMD EPYC 7H12 . techpowerup . Tillträdesdatum: 10 oktober 2021.
- ↑ AMD avslöjar sin mest kraftfulla 64-kärniga processor . iXBT.com . Hämtad 10 oktober 2021. Arkiverad från originalet 10 oktober 2021. (ryska)
- ↑ arkitektur - Hur man beräknar enkelprecisionsdata och dubbelprecisionsdata toppprestanda för Intel(R) Core™ i7-3770 CPU - Stack Overflow . Hämtad 15 oktober 2017. Arkiverad från originalet 22 oktober 2015. (obestämd)
- ↑ 1 2 Översikt över Intel® Advanced Vector Extensions 512 (Intel® AVX-512) . Hämtad 24 december 2019. Arkiverad från originalet 24 december 2019. (obestämd)
- ↑ Det angivna antalet instruktioner per cykel kan endast utföras av de äldre representanterna för dessa arkitekturer, som säljs under marknadsföringsnamnen Xeon Platinum och Xeon Gold från och med 6xxx-serien, som har två 512-bitars FMAC-block i varje kärna för exekvering av AVX -512 instruktioner. För alla juniormodeller: Xeon Bronze, Xeon Silver och Xeon Gold 5ххх, är ett av FMAC-blocken inaktiverat och därför reduceras den maximala exekveringshastigheten för flyttalsinstruktioner med 2 gånger.
- ↑ Flytpunktsbehandlingsenheten (FPU) delas per modul - ett par processorkärnor. När flytande operationer utförs samtidigt på båda kärnorna, delas det mellan dem.
- ↑ Kort beskrivning av Elbrus/Elbrus arkitektur . Hämtad 26 december 2019. Arkiverad från originalet 11 juni 2017. (obestämd)
- ↑ Denna mikroarkitektur tillhör VLIW -klassen och har 6 parallella kanaler för exekvering av instruktioner, varav 4 är utrustade med 64-bitars flyttalsenheter av typen FMAC .
- ↑ Elbrus-8S (TVGI.431281.016) / Elbrus-8S1 (TVGI.431281.025) - centralprocessor 1891VM10Ya / 1891VM028 / MCST . Hämtad 16 december 2017. Arkiverad från originalet 30 mars 2018. (obestämd)
- ↑ I den fjärde generationen av arkitekturen är 64-bitars FMAC-block redan tillgängliga på alla 6 kanalerna för instruktionsexekvering.
- ↑ Elbrus-8SV (TVGI.431281.023) - centralprocessor 1891VM12YA / MCST . Datum för åtkomst: 16 december 2017. Arkiverad från originalet 27 december 2019. (obestämd)
- ↑ I den 5:e generationen av arkitekturen ökades bitdjupet för alla FMAC-block från 64 till 128.
- ↑ Sergej Uvarov. Detaljerad recension och testning av Apple iPhone 5s . IXBT.com (23 september 2013). Arkiverad från originalet den 2 oktober 2013. (obestämd)
- ↑ Apple A8 SoC - NotebookCheck.net Tech . Hämtad 15 januari 2015. Arkiverad från originalet 20 december 2014. (obestämd)
- ↑ 1 2 Apple A10 - Jämförande specifikationer och CPU-riktmärken . Hämtad 22 januari 2022. Arkiverad från originalet 22 januari 2022. (obestämd)
- ↑ [3] Arkiverad 30 augusti 2017 på Wayback Machine // Gizmodo, 5/13/13: "Eftersom Bitcoin-gruvarbetare faktiskt gör en enklare typ av matematik (heltalsoperationer), måste du göra en liten (stökig) konvertering för att få till FLOPS. .. nya ASIC-gruvarbetare – maskiner .. gör inget annat än att bryta Bitcoins – kan inte ens göra andra typer av operationer, de är utelämnade helt och hållet.
- ↑ [4] Arkiverad 3 december 2013 på Wayback Machine // SlashGear, 13 maj 2013: "Bitcoinutvinning fungerar tekniskt sett inte med FLOPS, utan snarare heltalsberäkningar, så siffrorna konverteras till FLOPS för en konvertering som de flesta människor kan förstå mer. Eftersom omvandlingsprocessen är lite konstig, har det lett till att vissa experter har gjort fel på gruvsiffrorna."
- ↑ [5] Arkiverad 27 november 2013 på Wayback Machine // ExtremeTech: "Eftersom Bitcoin-brytning inte förlitar sig på flyttalsoperationer är dessa uppskattningar baserade på alternativkostnader. Nu när vi har hårdvara med applikationsspecifika integrerade kretsar (ASIC) designade från grunden för att inte göra något annat än att bryta Bitcoins, blir dessa uppskattningar ännu mer otydliga.”
- ↑ [6] Arkiverad 3 december 2013 på Wayback Machine // CoinDesk : "Två, uppskattningarna som används för att konvertera hash till floppar (som resulterar i cirka 12 700 floppar per hash) dateras till 2011, innan ASIC-enheter blev normen för bitcoin-utvinning. ASIC:er hanterar inte floppar alls, så den nuvarande jämförelsen är väldigt grov."
- ↑ [7] Arkiverad 3 december 2013 på Wayback Machine // VR-Zone: "En konverteringsfrekvens på 1 hash = 12,7K FLOPS används för att bestämma den allmänna hastigheten för nätverksbidraget. Uppskattningen skapades 2011, innan skapandet av ASIC-hårdvara enbart utformad för bitcoin-brytning. ASIC använder inte flyttalsoperationer alls,... Således har uppskattningen ingen verklig betydelse för sådan hårdvara.”
- ↑ Bitcoin Watch , arkiverad 2011-04-08: "Network Hashrate TFLOP/s 8007"
- ↑ BOINC Arkiverad 19 september 2010.
- ↑ BOINCstats:SETI@home Arkiverad från originalet den 3 maj 2012.
- ↑ BOINCstats:Einstein@Home . Hämtad 16 april 2012. Arkiverad från originalet 21 februari 2012. (obestämd)
- ↑ 12 konsolspecifikationer . _ Hämtad 7 december 2017. Arkiverad från originalet 10 april 2021. (obestämd)
- ↑ PSP Specs Revealed Bearbetningshastighet, polygonhastighet och mycket mer. Arkiverad 28 juli 2009 på Wayback Machine // IGN Entertainment, 2003. "PSP CPU CORE...FPU, VFPU (Vector Unit) @ 2.6GFlops"
- ↑ Uppdatering: Hur många FLOPS finns i spelkonsoler? Arkiverad 9 november 2010 på Wayback Machine // TG Daily, 26 maj 2008
- ↑ Cellbredbandsmotorarkitektur och dess första implementering . IBM developerWorks (29 november 2005). Hämtad 6 april 2006. Arkiverad från originalet 24 januari 2009. (obestämd)
- ↑ Utnyttja prestandan av 32-bitars flytande punktaritmetik för att erhålla 64-bitars noggrannhet . University of Tennessee (31 juli 2005). Hämtad 11 februari 2011. Arkiverad från originalet 18 mars 2011. (obestämd)
- ↑ Philip Wong . Xbox One vs. PS4 vs. Wii U [uppdatering ] (engelska) , CNET Asia, Games & Gear (22 maj 2013). Arkiverad från originalet den 3 december 2013. Hämtad 29 november 2013.
- ↑ Anand Lal Shimpi. Xbox One: Hardware Analysis & Comparison to PlayStation 4 (engelska) . Anandtech (22 maj 2013). Arkiverad från originalet den 2 oktober 2013.
- ↑ PS4-specifikation (länk ej tillgänglig) . Hämtad 22 juni 2013. Arkiverad från originalet 20 juni 2013. (obestämd)
- ↑ Specifikationer . Playstation. Hämtad 14 december 2018. Arkiverad från originalet 4 maj 2019. (ryska)
- ↑ Sony avslöjar nya PlayStation-specifikationer . RIA Novosti (20200318T2333+0300). Hämtad 20 mars 2020. Arkiverad från originalet 20 mars 2020. (ryska)
- ↑ Vad du kan förvänta dig av nästa generations spel . Xbox Wire (24 februari 2020). Hämtad 24 februari 2020. Arkiverad från originalet 24 februari 2020.
- ↑ Specifikationer för NVIDIA GeForce RTX 2080 Ti | TechPowerUp GPU-databas
- ↑ 1 2 3 4 Jämförelsetabeller för AMD (ATI) Radeon grafikkort . Hämtad 24 februari 2012. Arkiverad från originalet 28 februari 2012. (obestämd)
Länkar
{kind=link}
{kind=link}